문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
- 0ms 시점에 3ms가 소요되는 A작업 요청
- 1ms 시점에 9ms가 소요되는 B작업 요청
- 2ms 시점에 6ms가 소요되는 C작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.

한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.
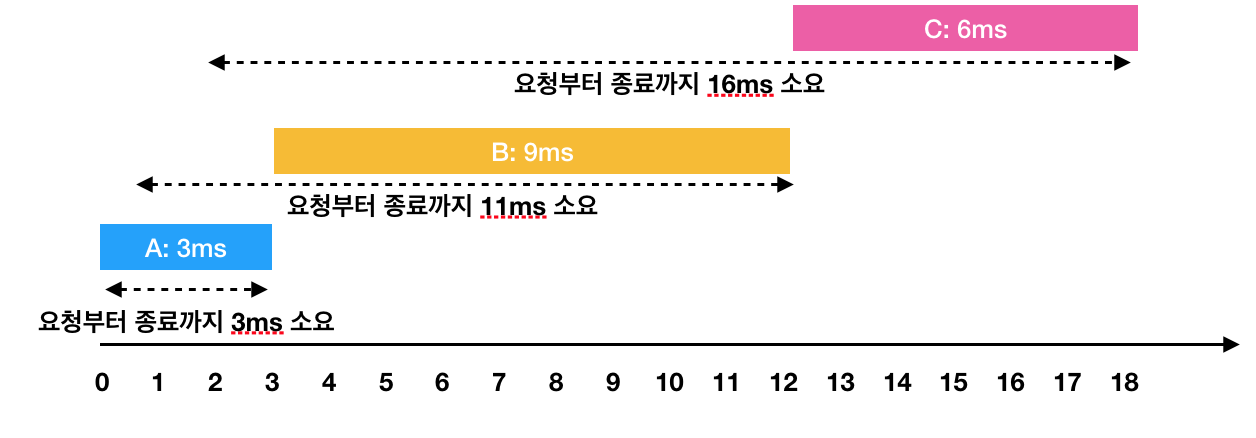
- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms)
- B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms)
- C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)
이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면

- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms)
- C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms)
- B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항- jobs의 길이는 1 이상 500 이하입니다.
- jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
- 각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
- 각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
| [[0, 3], [1, 9], [2, 6]] | 9 |
문제에 주어진 예와 같습니다.
- 0ms 시점에 3ms 걸리는 작업 요청이 들어옵니다.
- 1ms 시점에 9ms 걸리는 작업 요청이 들어옵니다.
- 2ms 시점에 6ms 걸리는 작업 요청이 들어옵니다.
문제가 정말 어렵다...
문제를 이해하고 어떻게 코드를 짤지 고민하는데도 시간이 오래 걸렸다.
아직까지 문제를 해결하지 못했고 어디가 잘못되었는지 점검하기 위해 아래와 같이 정리해본다.
작업 순서는 무조건 작업경과시간이 작은것부터 진행해야 시간이 제일 작아진다.
이유는 위예제들을 계산해보면 아래와 같이 나오는데
1. [A>C>B]
A : 3
C : 3 + 6 - 2 = 7
B : 3 + 6 + 9 - 1 = 17
3 + 7 + 17 = 27
2. [A>B>C]
A : 3
B : 3 + 9 - 1 = 11
C : 3 + 9 + 6 - 2 = 16
3 + 11 + 16 = 30
총 계산식을 비교해보면 다른 값은 다 똑같지만 A는 6을 2번, 2는 9를 2번 더해준 것이 보인다.
이것을 단서로 왜 저러한 식이 나왔나 정리를 해보면 아래와 같은 공식이 나온다.
※ 각 작업별 요청부터 종료까지의 소요시간
현재까지 한 작업들의 총합 + 이번에 작업의 경과시간 - 이번 작업의 요청시간
=> 작업이 끝난 당시의 시간(현재시간) - 이번 작업의 요청시간
이 값을 최소로 맞춰 주려면 현재까지 한 작업들의 총합을 최소로 맞춰주어야 하므로,
경과시간이 낮은 작업부터 진행해야 한다는 결론이 나온다.
여기서 몇가지 제한사항이 생기며 아래와 같이 해결하였다.
- 요청시간이 현재시간보다 클 경우 해당 작업은 실행할 수 없다.
>> 현재시간을 기준으로 작업이 가능한 내역을 만들어 놓고 내역 안에서 경과시간이 작은것부터 진행한다.
이 작업은 하나의 작업이 끝날때마다 갱신해줘야한다.
또한 작업 리스트 저장소는 우선순위 큐를 사용하여 매번 최소값을 poll할 예정 - 요청시간을 기준으로 검색할때 어떤 자료구조에서든지 x 보다 작은 값을 가져오는 것은 시간복잡도를 요구한다.
(현재 시간보다 작은 요청시간을 가지고 있는 작업들을 가져와야하기 때문에)
>> HashMap을 사용하여 각 작업들의 요청시간을 key로 지정하여 검색 효율성을 높이고, 만약 중복 요청시간이
존재할 수 있기 때문에 value에 LinkedList를 사용해서 여러값을 저장할 수 있도록 한다.
(검색할때 모든 값을 가져오기 때문에 배열갯수가 정해져있지 않고 추가에 유리한 LinkedList를 사용하였다) - 각각의 요청시간을 매번 계산하려면 작업을 할때마다 그 작업의 요청시간이 몇인지 확인해야한다.
>> 계산식을 살펴보면 순서에 상관없이 모든 요청시간이 한번씩 감소하기 때문에 한번에 몰아서 뺴주면 된다.
위와 같은 계획을 토대로 프로세스를 정리하자면
- Map<Integer(요청시간), List<Integer(경과시간)>>에 jobs를 옮긴다. (요청시간이 중복될 경우 경과시간리스트 추가)
- 작업을 진행하면서 answer의 초기값에 모든 요청시간을 빼준다. (마지막에 반복 또 돌리기 귀찮아서..)
- 현재시간과 비교하려면 요청시간이 작은값들부터 비교하기 때문에 요청시간이 작은값부터 추출할 수 있는
PriorityQueue<Integer> requsetTimes라는 변수를 선언한다. - 요청이 들어온 작업들을 저장하기 위한 PriorityQueue<Integer> todoList라는 변수를 선언한다.
- 현재시간이 언제인지 확인할 변수 int currentTime 변수를 선언한다.
- requestTimes와 todoList에 있는 값을 전부 처리할때까지 아래 작업 반복 실행
- 현재시간보다 작은 요청시간들의 작업들을 todoList로 던진다.
- todoList의 작업들을 아래와 같이 진행한다.
- 작업의 경과시간을 currentTime에 더해준다.
- answer에 currentTime을 더해준다.
- 위 같은 반복을 끝내면 answer는 작업들이 끝나는 시점의 시간들을 모두 더했을것이고,
요청시간은 처음에 모두 빼줬기 때문에 3으로 나누어 return하면 종료된다.
아래는 위 프로세스를 코드로 작성한 것이다.
어디가 잘못되었는지 조금 더 유심히 살펴보고 다시 작성해보아야겠다.
public int Q2(int[][] jobs) {
int answer = 0;
// 경과시간을 기준으로 작업목록을 지정한다.
// 요청시간, 경과시간 목록
Map<Integer, List<Integer>> entityMap = new HashMap<>();
for (int[] i : jobs) {
// 1. entity 추가 작업
// key가 있을 경우 요청시간에 경과시간을 추가해준다.
if (entityMap.containsKey(i[0])) {
entityMap.get(i[0]).add(i[1]);
} else {
List<Integer> tmp = new LinkedList<>();
tmp.add(i[1]);
entityMap.put(i[0],tmp);
}
answer -= i[0];
}
// 요청시간들을 모아 놓은 변수
PriorityQueue<Integer> requestTimes = new PriorityQueue<>(entityMap.keySet());
// 진행할수 있는 작업들의 경과시간
PriorityQueue<Integer> todoList = new PriorityQueue<>();
//변수
int currentTime = 0; //현재 시간 (해당 시간을 기준으로 요청시간이 값들을 추리기 위한 변수, 초기값:0)
while (!requestTimes.isEmpty() || !todoList.isEmpty()) {
// 현재 시간보다 작은 요청시간의 작업들을 todoList로 작업 넘겨주기
while (!requestTimes.isEmpty() && currentTime >= requestTimes.peek()) {
for (int i : entityMap.get(requestTimes.poll())) {
todoList.add(i);
}
}
// 작업 진행
if (!todoList.isEmpty()) {
currentTime += todoList.poll();
answer += currentTime;
}
}
return answer /3;
}
요새 피곤해서 그런지 정말 어이없는부분에서 놓친 부분이 있었다.
평균을 구하는건데 answer / 3을 리턴하는건줄알고 정말 많이 헤맸다 -_-;;;
덕분에 블로그에 자세하게 정리하기도하고, 우선순위큐의 사용법이 익숙해진건 좋지만...
아무튼 푹 쉬고 맑은 정신으로 다음문제부터 풀어봐야할듯..
'CodingPractice' 카테고리의 다른 글
| [프로그래머스] K번째수 (0) | 2021.12.30 |
|---|---|
| [프로그래머스] 이중우선순위큐 (0) | 2021.12.26 |
| [프로그래머스] 더 맵게 (0) | 2021.12.24 |
| [프로그래머스] 주식가격 (0) | 2021.12.18 |
| [프로그래머스] 다리를 지나는 트럭 (0) | 2021.12.18 |




댓글